Frequently Asked Questions
- How can I check which SQLWATCH version I’m running?
- Why is
date_last_seennot showing the correct date. - How does SQLWATCH capture T-SQL Queries
- How to reduce the SQLWATCH database size
How can I check which SQLWATCH version I’m running?
The table [dbo].[sqlwatch_app_version] is update every time you install or upgrade the application:
SELECT [install_sequence]
,[install_date]
,[sqlwatch_version]
FROM [dbo].[sqlwatch_app_version]
To See the currently installed version, you can use the view [dbo].[vw_sqlwatch_app_version] which simply returns the most recent row from the table above.
In addition, SQLWATCH version and other information is written in the database extended properties. To see it, right click on the database, click properties and select extended properties. You can also get extended properties from system views:
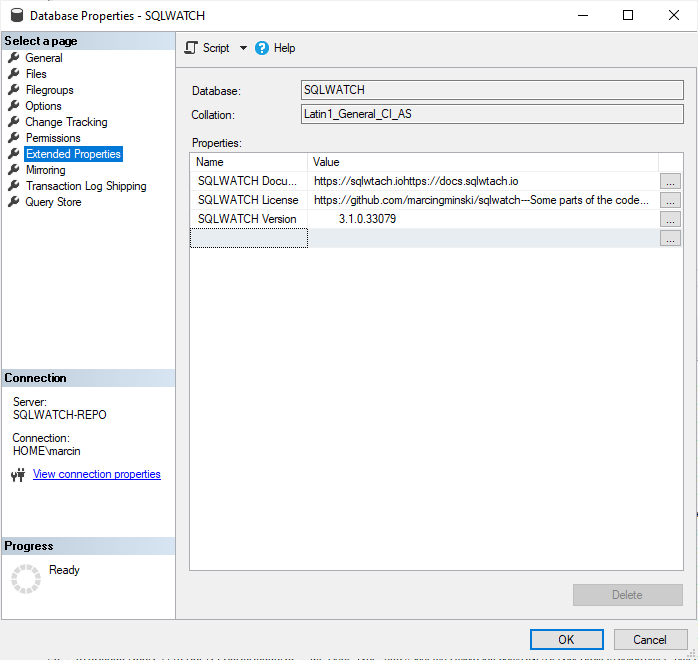
select *
from sys.extended_properties
where class = 0
Why is date_last_seen not showing the correct date.
This field is on some of the sqlwatch_meta* tables and used to remove old items as part of the retention process. By default, anything “not seen” in over 32 days will be removed. When the any of the meta tables is merged, this field is also updated for any matched rows to ensure they are not deleted as part of the retention process. Any new rows have the date_last_seen set as getutcdate()
merge table_target as target
using table_source as source
on target.column = source.column
when matched then
update set date_last_seen = getutcdate()
when not matched then
insert (column, date_last_seen)
values (value, getutcdate())
Since the version 3.x, the SqlWatchImport.exe is also using this field when importing data to limit the number of rows and to speed up the import. On systems where both, the SqlWatchImport.exe and the merge run frequently we would be importing the same data with every run. To speed up the import process, we are delaying the update of the date_last_seen until it at least 24 hours old:
merge table_target as target
using table_source as source
on target.column = source.column
when matched then and datediff(hour,date_last_see,getutcdate()) > 24
update set date_last_seen = getutcdate()
when not matched then
insert (column, date_last_seen)
values (value, getutcdate())
How does SQLWATCH capture T-SQL Queries
I believe that there is no point capturing the entire workload as part of your BAU monitoring, instead we should focus on the queries that cause troubles. Long query does not always mean it’s a bad query. For example, a long import of large data set, or DBCC checks, or backups will all take few or more minutes to complete. Queries that could cause trouble are those that prevent other queries from running i.e. blockers, and those that encounter excessive, bad waits.
WAITS mean that the SQL Server was not able to serve the query on time and it had to wait for the resource to become available. The query could be waiting for a number of reasons, it could be the storage (IO), CPU, Locks, and all sorts of things. Waits happen because the SQL Server is not fast enough for what you are trying to do or the query is poorly written. There are cases were the first is true, i.e. slow storage will cause lots of IO related waits but 95% of the time the queries are just poor, or a combination of both.
Although the word “excessive” will mean different things for different people, I coded SQLWATCH to capture queries with WAITS longer than 1 second. Normally, waits should only last few milliseconds. A constant wait for over 1 second could (but does not have to) indicate problems.
If you have a busy server with lots of queries lasting over 1 second you may want to tweak the XES and increase the time to 2 or more seconds, or tune your queries.
If you want to capture and analyse your entire workload, there are tools designed to do just that, such as WorkloadTools by Gianluca Sartori.
How to reduce the SQLWATCH database size
You can reduce the size by applying data and index compression. Please check the configuration section for details. Compression can drastically remove table and index size.
Please note that depending on the deployment method, the compression may be removed when upgrading SQLWATCH. This is due to the declarative deployment model where data and index compression is not enabled on the database project.
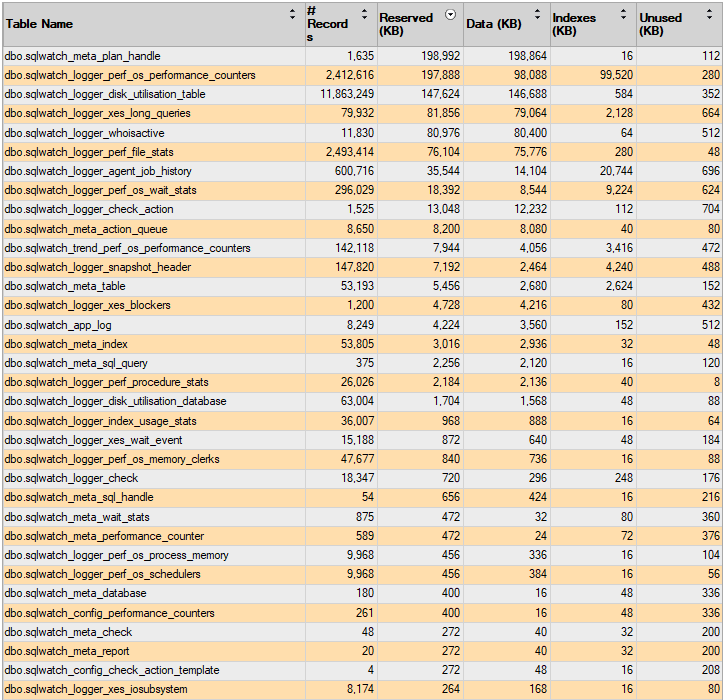
The below examples show SQLWATCH database with 30 days worth of data on a server with 180 databases and 53000 (53k) tables.
Compression disabled, ordered by Reserved:
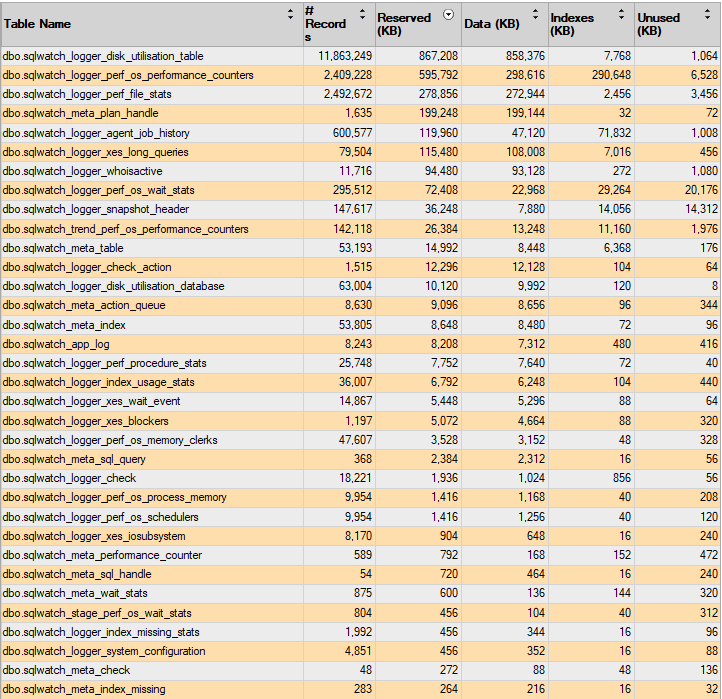
Data and Index compression enabled, ordered by Reserved: